
In this post, I examine the incident journey through the perspective of the Atlassian ecosystem, a platform widely recognized for streamlining agile incident management.
Feel free to contribute in the comments if I’ve missed any essential aspects of the process. Your insights and experiences are always welcome!
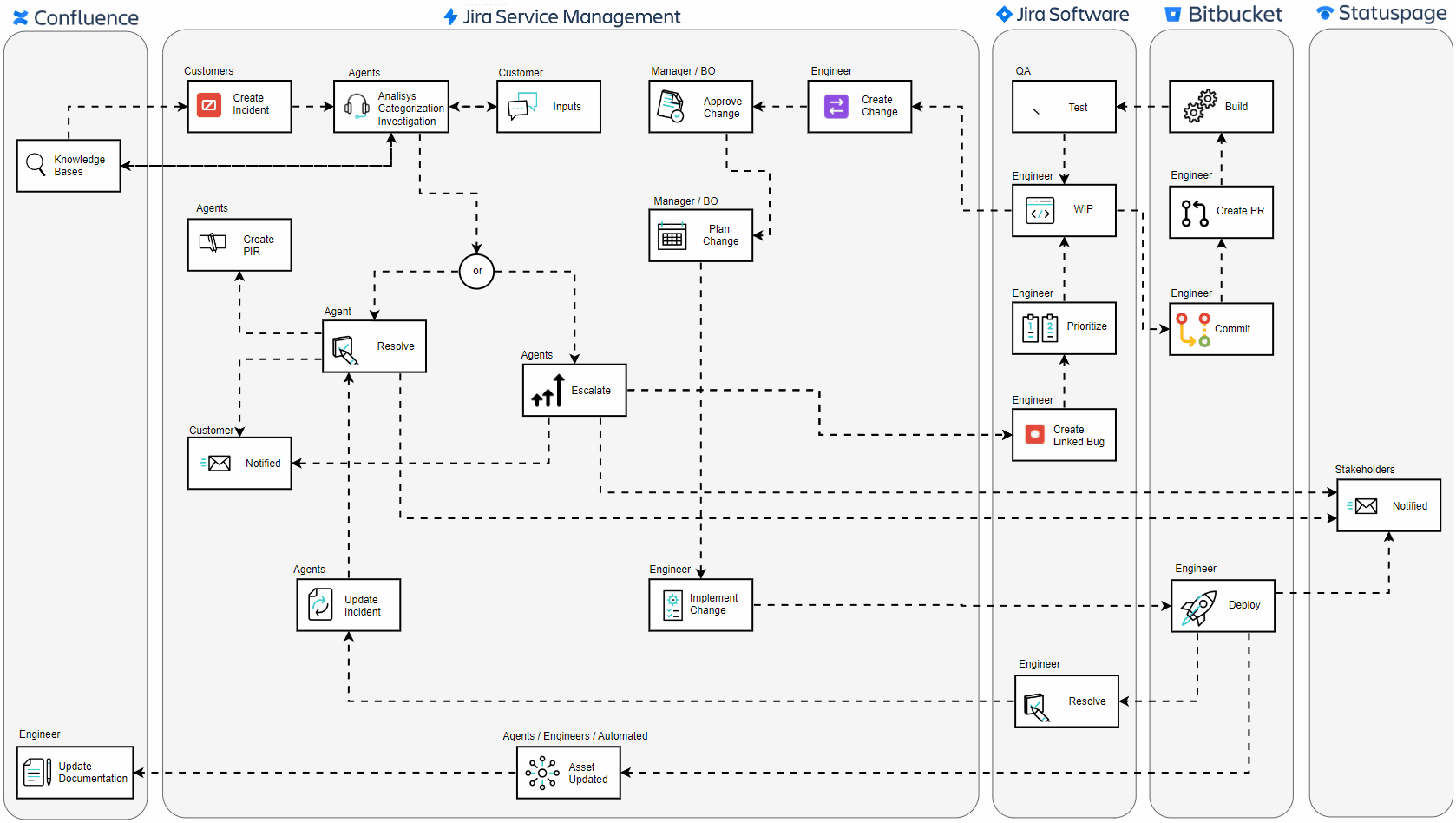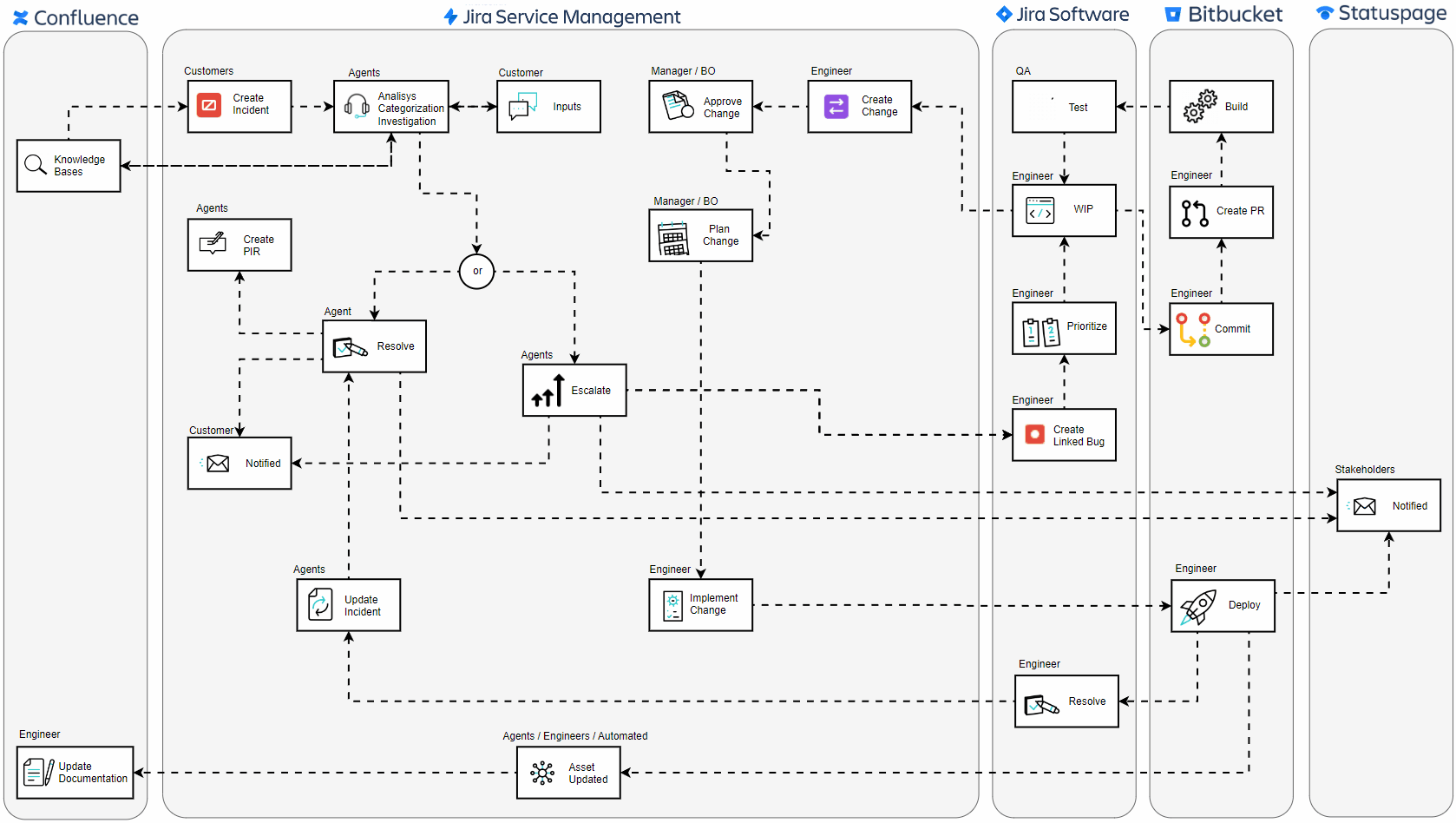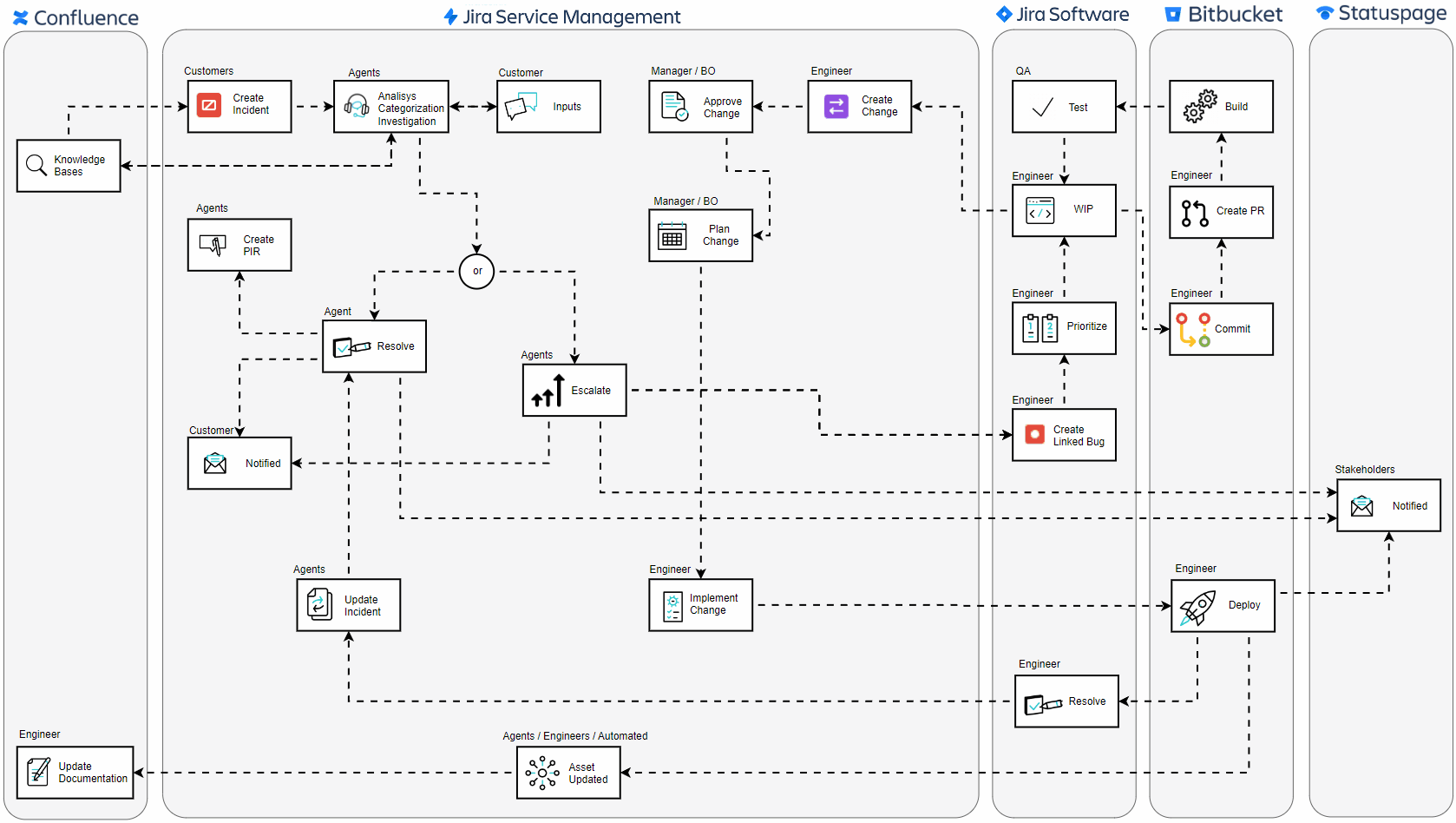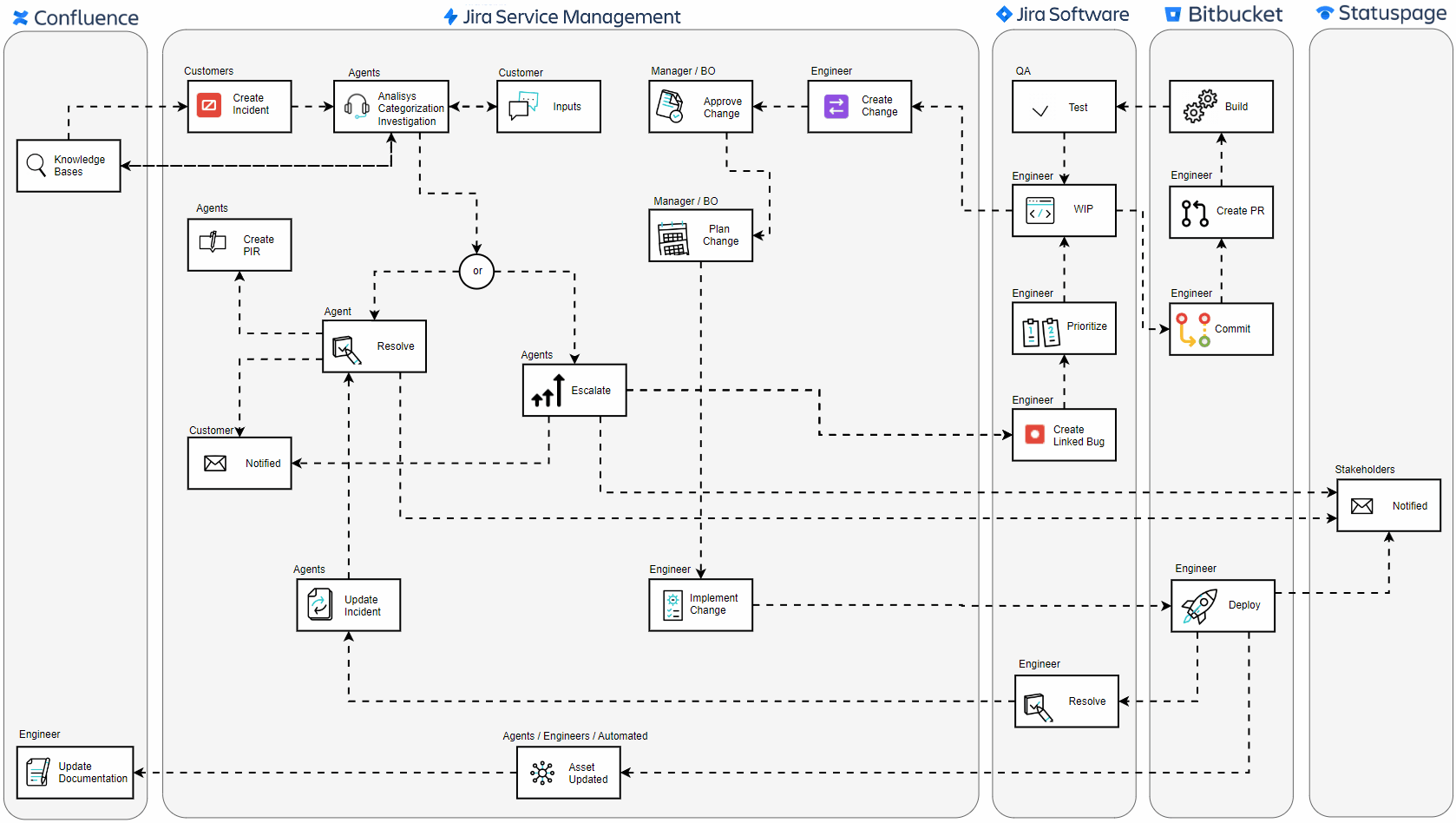
🔍 Incident Reporting with Proactive Knowledge Sharing: The journey begins the moment an end-user encounters a disruption. As users start the process of creating a ticket, the portal dynamically displays potential solutions and troubleshooting steps from Confluence, potentially resolving issues before a ticket is ever submitted. If the provided information doesn’t address the problem, the user can proceed to log the incident, ensuring the service team is alerted and ready to assist.
🛠️ Issue Categorization and Investigation: Service desk agents focus on restoring service as quickly as possible, ensuring minimal disruption to the business. They categorize the incident and work to resolve it efficiently using knowledge bases hosted on Confluence, which provide essential information. Root cause analysis, however, falls under the purview of problem management, which steps in to thoroughly investigate and address the underlying causes of the incident.
⚙️ Technical Escalation: When an issue surpasses the threshold of initial support capabilities, it is escalated to more specialized personnel. These experts, often engineers, then step in, equipped with Jira Software for bug tracking and Bitbucket for source code management.
🔧 Development and Peer Review: The team employs Kanban or Scrum methodologies within Jira to prioritize and systematically work on these bugs, ensuring agile response and focus on the most pressing issues first. In this critical phase, engineers commit to code changes and conduct peer reviews through Bitbucket’s pull requests.
- Software Teams may also use Compass as their software inventory.
- Here, Clover can come into play, providing insights into test coverage and ensuring that all new code meets quality standards.
- It can also be used SourceTree to check out and manage code in Git.
🧪 Quality Control: A rigorous testing phase follows, where Quality Assurance teams validate the functionality and stability of the fix, ensuring that the resolution is solid and no additional issues have been introduced.
- Apps like Xray can be used here to facilitate the process.
✅ Change Approval Process: Any change that stems from an incident must be authorized. Managers or Business Owners review the proposed changes, considering the broader impact on the system before giving their stamp of approval. Additionally, other teams such as security, compliance, and operations may also be involved in the review process to ensure that all aspects of the change are thoroughly vetted and align with organizational policies and standards.
📝 Plan Change: Before implementing any changes, it’s essential to develop a comprehensive plan that outlines the steps, timelines, and potential risks associated with the change. This plan is typically created in collaboration with relevant teams, including service desk agents, engineers, security, and operations. The plan should detail the scope of the change, the resources required, potential impacts on the system, and contingency measures. Once the plan is thoroughly reviewed and approved by all stakeholders, it serves as the blueprint for executing the change in a controlled and coordinated manner, minimizing the risk of further disruptions.
🌐 Implementing the Change: Once approved, engineers implement the change. Whether it’s a hotfix or a scheduled update, it’s done methodically to minimize further disruptions.
🔄 Resolution and Deployment: The final code is deployed to the production environment. The deployment is carefully monitored to ensure success, marking the incident’s resolution once stability is confirmed.
📢 Stakeholder Communication: Communication is key throughout the incident journey. Stakeholders are consistently informed about the status through Statuspage, ensuring transparency and building trust.
📝 Post-Incident Reviews (PIR): After resolution, the focus shifts to learning and improvement. Teams engage in Post-Incident Reviews to dissect the event, extract lessons, and document actionable steps to prevent future occurrences.
📚 Documentation Update: After the storm has settled, documentation is updated. This vital step ensures that the incident’s knowledge is captured and becomes part of the collective intelligence for future reference.
🎓 Continuous Learning: The incident journey concludes, but the learning never stops. Each incident enriches the organization’s experience, sharpening the reflexes for future encounters, and contributing to a culture of continuous improvement.
